
Depuis plus de dix ans, l’IRT Saint Exupéry accompagne des projets de recherche en lien avec les « Systèmes Embarqués Critiques » via un centre de compétence dédié. Dans les articles précédents, nous avons évoqué les évolutions récentes des processeurs utilisées dans les systèmes embarqués.
Défi n°1 : Programmer de manière optimale les plateformes numériques
Nous avons notamment montré comment l’introduction du parallélisme a permis de continuer à améliorer les performances de ces processeurs en dépit des contraintes physiques liées à la dissipation thermique. Nous avons aussi abordé les difficultés posées par ces composants du point de vue temporel. Nous y reviendrons longuement dans de futurs articles. Cependant, si la maîtrise du temps est une préoccupation majeure pour tout système temps-réel, la première difficulté qu’un ingénieur va rencontrer est de programmer ces plateformes afin d’en exploiter au mieux les capacités…
Or, comme nous l’avons déjà souligné, ces processeurs comportent désormais de multiples unités de traitement : cœurs, accélérateurs graphiques, accélérateur IA, unité de traitement du signal, etc. Certains de ces composants incluent même des zones FPGA (Field Programmable Gate Array) permettant de déployer des structures de calcul très proches de celles que l’on obtiendrait avec du matériel.
Accélérer les traitements sur ces processeurs grâce à la combinaison de deux stratégies
La première stratégie consiste à découper les traitements en éléments que l’on pourra déployer sur différentes unités de traitement afin d’en paralléliser l’exécution. C’est ce qui se passe sur un processeur multicœur : à chaque un instant, un cœur traite une instruction appartenant à un fil d’exécution logiciel (thread) et n cœurs exécutent simultanément n instructions.
Si le nombre de cœurs des processeurs utilisés dans les systèmes embarqués actuels reste encore limité (4, 8,…), certains processeurs embarquables présentent un nombre bien plus important d’unités de traitement. On peut ainsi mentionner les manycoeur du type MPPA de Kalray ou les GPGPU (General Purpose Graphical Processing Units) du type Jetson de NVIVDIA.
La seconde stratégie consiste à déployer un traitement sur la structure matérielle la plus adaptée à la nature de ce traitement. Ainsi, par exemple, un filtre numérique sera déployé sur un DSP (Digital Signal Processor) ou un FPGA et une convolution sera déployée sur un GPU ou un accélérateur IA pour y être accélérés.
Une architecture complexe des processeurs

En vérité, le problème est encore plus complexe car les unités de traitement d’un même type (par ex. des cœurs de CPU) s’organisent elles-mêmes en familles présentant des caractéristiques homogènes et spécifiques concernant leur capacité à offrir des garanties temporelles, leur capacité à travailler en paire (lock-step) ou leur capacité de traitement ou leur consommation énergétique. Ainsi, chez Arm par exemple, les cœurs s’organisent en familles : X pour les cœurs les plus performants, A pour les cœurs dédiés aux traitements applicatifs, R pour les cœurs « temps-réel » et M pour les microcontrôleurs. Un processeur peut donc combiner sur une même puce des cœurs de familles différentes : par exemple des cœurs A et des cœurs R afin de couvrir au mieux les cas d’usage envisagés pour ce processeur. Ce nouveau degré de liberté étend les possibilités d’optimisation des performances, mais complexifie aussi le travail de l’architecte et du développeur logiciel.
Pour eux, le problème ne consiste donc plus uniquement à produire un algorithme séquentiel qui réalisera la fonction attendue, mais à exposer autant que possible le parallélisme intrinsèque de l’application afin de maximiser les opportunités de déploiement et offrir le choix de la solution optimale.
Parlons du parallélisme des applications
Actuellement, la majeure partie des développements utilisent encore le langage C ou C++ qui n’offrent que des moyens assez primitifs et macroscopiques pour exposer le parallélisme des applications. En pratique, on utilise par exemple le concept de thread qui n’est vraiment adapté qu’à une expression « gros-grain » du parallélisme. Par exemple, le parallélisme de boucle – celui que l’on peut extraire lors d’un calcul de multiplication de matrices – ne peut être capturé facilement au moyen de threads. En vérité, le langage manquant d’expressivité, le programmeur doit faire appel à des bibliothèques externes (souvent désignées par API pour Application, Programming Interfaces) pour pallier ce manque.
Or, le besoin de parallélisme existe depuis bien longtemps dans le monde du calcul haute performance (High Performance Computing ou HPC). Dans ce contexte, des langages spécifiques et des extensions des langages traditionnels maîtrisés par une large communauté ont été introduits depuis des décennies.
Parallélisme des applications : focus sur OpenMP
OpenMP est l’une de ces extensions. Elle ajoute au langage C ou C++ un ensemble d’annotations (des pragmas) permettant d’indiquer que telle boucle doit être parallélisée, telle donnée doit être protégée, etc. Au fil des évolutions du standard, l’expressivité s’est accrue et la dernière version d’OpenMP offre des constructions pour exprimer le parallélisme de tâche et offre la capacité à déporter des traitements du processeur hôte vers des accélérateurs spécifiques.
Ce mécanisme d’annotation permet une approche très incrémentale du processus d’optimisation. En effet, le programmeur élabore tout d’abord son algorithme de façon séquentielle – ce qui reste tout de même la façon la plus simple pour un humain d’exposer un calcul – et en valide les résultats au moyen de tests (par exemple). Puis, dans une seconde phase, il peut alors exposer les opportunités de parallélisation et ajouter les mécanismes de protection d’accès aux données au moyen des annotations d’OpenMP et revalider son code dans cette configuration, par exemple en comparant « dos-à-dos » les deux implémentations. Finalement, il peut aborder la troisième et dernière étape dans laquelle il peut choisir le code à déporter sur tel ou tel accélérateur et, à nouveau, revalider le comportement de son application.
La programmation des nouvelles plateformes de traitement au sein de l’IRT Saint Exupéry

Dans ce contexte, nos travaux ont porté sur l’exploitation de ces mécanismes pour le développement de systèmes embarqués. Nous avons tout d’abord étudié le fonctionnement du mécanisme logiciel (runtime) d’OpenMP et l’avons mis en œuvre – de façon restreinte – pour un exécutif temps réel de type ARINC 653 utilisé dans le monde aéronautique. Puis, en collaboration avec la société SpaceCodesign (www.spacecodesign.com), nous avons développé un outil logiciel – TOAST – permettant d’exploiter les annotations OpenMp pour déporter des traitements sur FPGA, grâce à la synthèse de haut niveau (HLS).
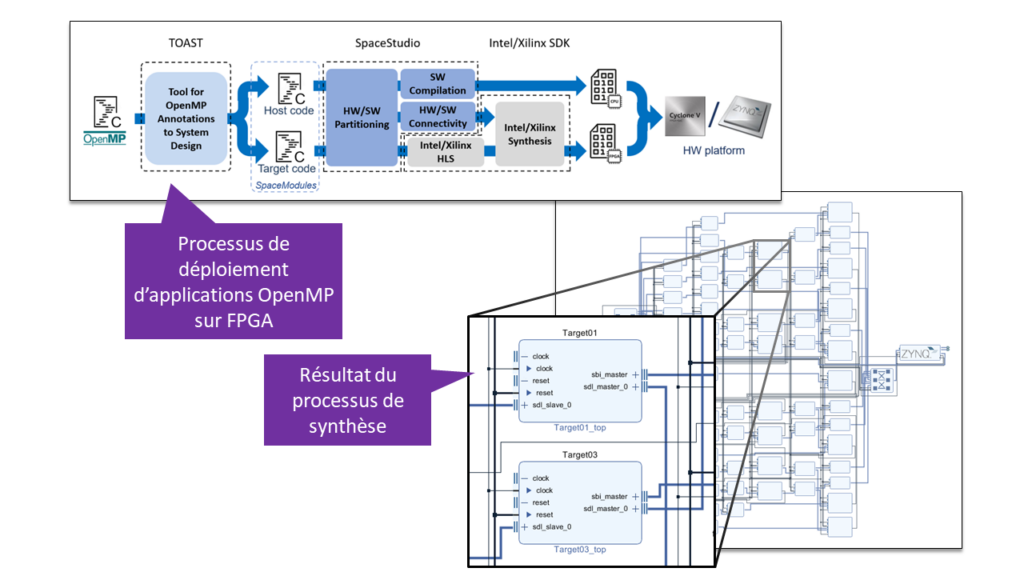
L’application au sein du projet ESA « LIONESS »
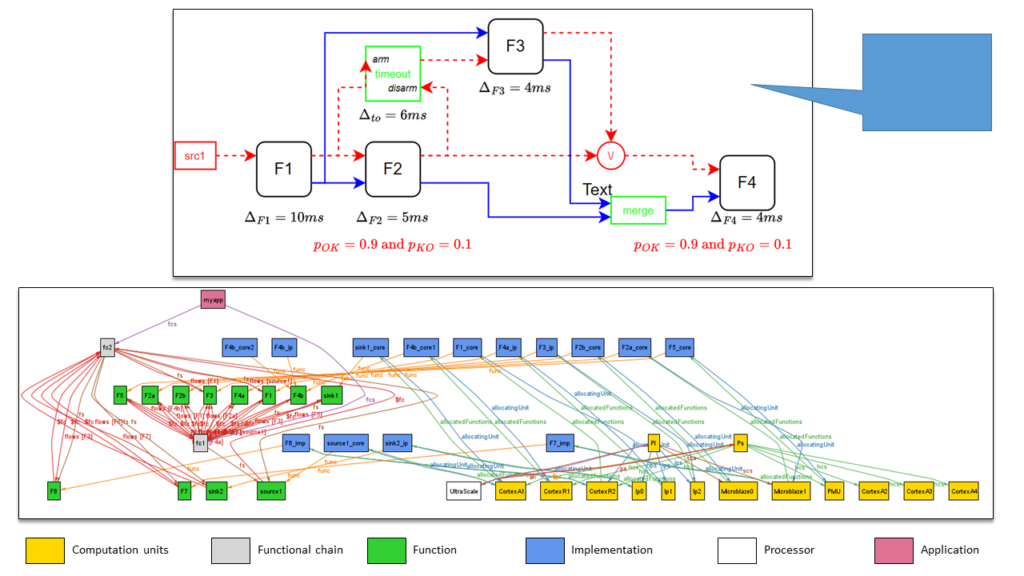
Plus récemment, dans le cadre du projet ESA OSIP « LIONESS » piloté par avec le Barcelona Supercomputing Center () et en collaboration avec SpaceCodesign et Airbus Defence and Space, nous avons combiné la capacité de décrire et déporter les traitements avec celle de décrire et mettre en œuvre des schémas de redondance logicielle, spatiale et temporelle. Ainsi, en combinant toutes les constructions du jeu d’annotation, il devient facile d’écrire une architecture comportant, par exemple, trois composants redondants et déployés l’un sur un cœur A, l’autre sur un cœur R et le troisième sur FPGA. Un exemple d’une telle architecture est présentée sur la figure 2. Ce schéma décrit le modèle d’évaluation permettant d’évaluer la probabilité de défaillance de l’architecture.
OpenMP est une solution pour exposer et exploiter le parallélisme des nouvelles plateformes matérielle. Ce n’est évidemment pas le seul moyen. En outre, si cette solution facilite l’exploitation des processeurs modernes, elle ne résout pas les problèmes spécifiques posés par le parallélisme et la concurrence tels que les interblocages (deadlock) ou les courses critiques (race conditions). Nous verrons dans un prochain article comment d’autres familles de langage, les langages synchrones, résolvent ces problèmes…
L’IRT Saint Exupéry, acteur des systèmes embarqués critiques
L’IRT Saint Exupéry joue un rôle clé dans le développement des logiciels pour l’aéronautique et le spatial à travers son Centre de Compétence « Systèmes embarqués critiques » (CSEC). En étroite collaboration avec ses partenaires industriels et académiques, ce pôle d’activités œuvre à l’amélioration continue des technologies embarquées pour répondre aux défis du secteur.
Pour aller plus loin…
Romain Leconte, Eric Jenn, Guy Bois, Hubert Guérard. Make Life Easier for Embedded Software Engineers Facing Complex Hardware Architectures – Proceeding of the 10th European Congress on Embedded Real Time Systems (ERTS 2020), Jan 2020, Toulouse, France.
Sara Royuela (1) , Franck Wartel (2), Sylvain Tiberio (2), Eric Jenn (3), Hubert Guérard (4), Guy Bois (4), ESA-2-1880 « LIONESS: Improving and leveraging OpenMP for the efficient and safe use of new high-performance hardware platforms | BSC-CNS », (1) Barcelona Supercomputing Center, (2) Airbus Defence and Space, (3) IRT Saint Exupéry, (4) Space Codesign
Pour retrouver tous nos articles dédiés à ce sujet :
- Article 1 : « Vers des systèmes logiciels et matériels plus sûrs«
- Article 2 : « L’analyse temporelle des systèmes embarqués »
- Article 3 : « De la multitude à l’harmonie : programmation pour les nouvelles plateformes »