
For more than ten years, the IRT Saint Exupéry has been supporting research projects related to ‘Critical Embedded Systems‘ through a dedicated competence center. In previous articles, we discussed recent developments in processors used in embedded systems.« Systèmes Embarqués Critiques » via un centre de compétence dédié.
Challenge #1: Optimally programming digital platforms
We specifically demonstrated how the introduction of parallelism has made it possible to continue improving processor performance despite the physical constraints related to heat dissipation. We also addressed the temporal challenges posed by these components, which we will explore further in future articles. However, while time management is a major concern for any real-time system, the first challenge an engineer will face is programming these platforms to make the most of their capabilities…
However, as we have already pointed out, these processors now feature multiple processing units: cores, graphics accelerators, AI accelerators, signal processing units, etc. Some of these components even include FPGA (Field Programmable Gate Array) areas, allowing the deployment of computing structures very close to those achievable with dedicated hardware.
Speeding up processing on these processors through the combination of two strategies
The first strategy involves breaking down processing tasks into elements that can be deployed across different processing units to parallelize execution. This is how a multicore processor operates: at any given moment, each core processes an instruction belonging to a software execution (thread), and n cores execute n instructions simultaneously.
While the number of cores in processors used in embedded systems remains relatively limited (4, 8, etc.), some embedded processors feature a significantly higher number of processing units. Examples include manycore processors like Kalray’s MPPA or GPGPUs (General Purpose Graphical Processing Units) such as NVIDIA’s Jetson.
The second strategy involves deploying a task onto the hardware structure best suited to its nature. For example, a digital filter would be deployed on a DSP (Digital Signal Processor) or FPGA, while a convolution would be deployed on a GPU or AI accelerator to be accelerated.
A complex processor architecture

In reality, the problem is even more complex because the processing units of the same type (e.g., CPU cores) are themselves organized into families, each with homogeneous and specific characteristics regarding their ability to offer temporal guarantees, their capacity to work in lock-step pairs, their processing power, or their energy consumption. For instance, at Arm, cores are organized into families: X for the most powerful cores, A for cores dedicated to application processing, R for ‘real-time’ cores, and M for microcontrollers. A processor can thus combine cores from different families on the same chip: for example, A cores and R cores, to best cover the intended use cases for that processor. This new degree of freedom expands performance optimization possibilities but also complicates the work of both the architect and the software developer.
For them, the problem is no longer just about producing a sequential algorithm that performs the expected function, but rather about exposing as much of the application’s intrinsic parallelism as possible in order to maximize deployment opportunities and offer the choice of the optimal solution.
Let’s talk about application parallelism
Currently, most developments still use the C or C++ language, which only provide rather primitive and macroscopic means to expose application parallelism. In practice, the concept of threads is used, which is really only suited for expressing ‘coarse-grained’ parallelism. For instance, loop parallelism—such as that which can be extracted during a matrix multiplication calculation—cannot be easily captured using threads. In fact, due to the language’s lack of expressiveness, the programmer has to rely on external libraries (often referred to as APIs for Application Programming Interfaces) to compensate for this shortcoming.
However, the need for parallelism has long existed in the world of high-performance computing (HPC). In this context, specific languages and extensions to traditional languages, mastered by a wide community, have been introduced for decades.
Application parallelism: focus on OpenMP
OpenMP is one of these extensions. It adds a set of annotations (pragmas) to the C or C++ language, allowing the programmer to specify that a certain loop should be parallelized, certain data should be protected, and so on. As the standard has evolved, expressiveness has increased, and the latest version of OpenMP offers constructs to express task parallelism and the ability to offload processing from the host processor to specific accelerators.
This annotation mechanism allows for a very incremental approach to the optimization process. Indeed, the programmer first develops the algorithm in a sequential manner—which is still the simplest way for a human to expose a calculation—and validates the results through tests (for example). Then, in the second phase, they can expose parallelization opportunities and add data access protection mechanisms through OpenMP annotations, revalidating the code in this configuration, for example by comparing the two implementations side by side. Finally, they can approach the third and final step, where they choose which code to offload to specific accelerators and, once again, revalidate the behavior of the application.
The programming new processing platforms within IRT Saint Exupéry

In this context, our work focused on exploiting these mechanisms for the development of embedded systems. First, we studied the operation of the OpenMP software mechanism (runtime) and implemented it—on a limited scale—for a real-time executive of the ARINC 653 type used in the aerospace industry. Then, in collaboration with the company SpaceCodesign (www.spacecodesign.com), we developed a software tool—TOAST—that allows the use of OpenMP annotations to offload processing onto FPGA, through high-level synthesis (HLS).
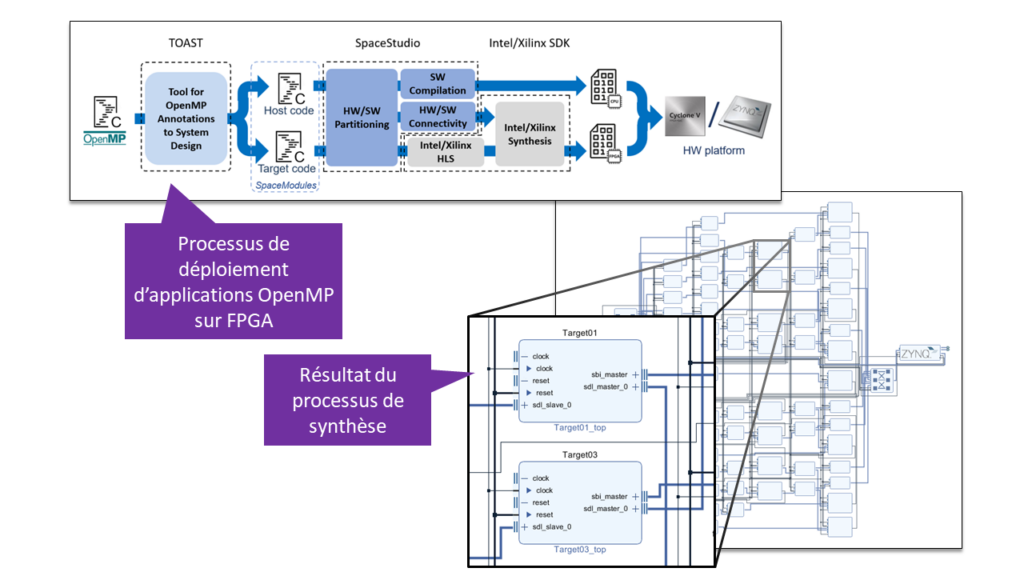
The application within the ESA project ‘LIONESS’
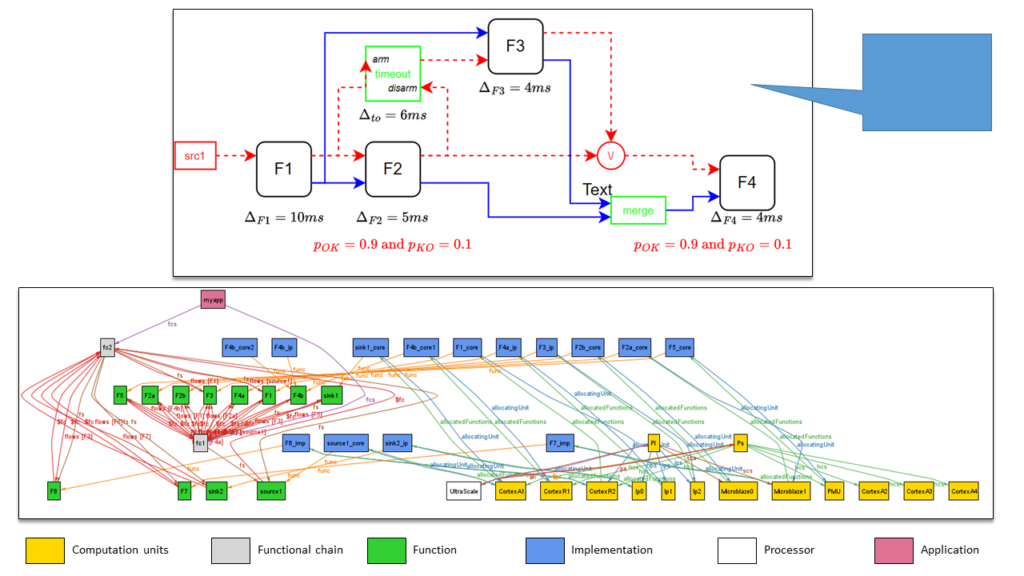
More recently, as part of the ESA OSIP project ‘LIONESS‘, led by the Barcelona Supercomputing Center (BSC) and in collaboration with SpaceCodesign and Airbus Defence and Space, we combined the ability to describe and offload processing tasks with the ability to describe and implement software, spatial, and temporal redundancy schemes. By combining all the constructs of the annotation set, it becomes easy to write an architecture that, for example, includes three redundant components deployed on one core of type A, another on a core of type R, and the third on FPGA. An example of such an architecture is presented in Figure 2. This diagram illustrates the evaluation model used to assess the failure probability of the architecture.
OpenMP is a solution for exposing and exploiting the parallelism of new hardware platforms. However, it is certainly not the only approach. Furthermore, while this solution makes it easier to exploit modern processors, it does not solve the specific problems posed by parallelism and concurrency, such as deadlocks or race conditions. In a future article, we will explore how other language families, such as synchronous languages, address these issues…
IRT Saint Exupéry, a key player in critical embedded systems
IRT Saint Exupéry plays a key role in the development of software for aerospace and space through its ‘Critical Embedded Systems’ (CSEC) Competence Center. In close collaboration with its industrial and academic partners, this activity hub works on the continuous improvement of embedded technologies to meet the challenges of the sector.
To go further…
Romain Leconte, Eric Jenn, Guy Bois, Hubert Guérard. Make Life Easier for Embedded Software Engineers Facing Complex Hardware Architectures – Proceeding of the 10th European Congress on Embedded Real Time Systems (ERTS 2020), Jan 2020, Toulouse, France.
Sara Royuela (1) , Franck Wartel (2), Sylvain Tiberio (2), Eric Jenn (3), Hubert Guérard (4), Guy Bois (4), ESA-2-1880 « LIONESS: Improving and leveraging OpenMP for the efficient and safe use of new high-performance hardware platforms | BSC-CNS », (1) Barcelona Supercomputing Center, (2) Airbus Defence and Space, (3) IRT Saint Exupéry, (4) Space Codesign
To find all our articles dedicated to this topic:
- Article 1 : “Towards safer software and hardware systems“
- Article 2 : “Time analysis of embedded systems”
- Article 3 : “From multitude to harmony: programming for new platforms”